

Your product team just mapped out Q2 deliverables. Engineering blocked their calendars. Design started wireframes. Then Monday morning hits and three VPs independently message you about "quick fixes" that absolutely cannot wait.
Most teams handle this terribly. They either become the Department of No (damaging stakeholder relationships) or the Department of Yes (destroying their roadmap). Teams that survive this treat ad-hoc requests like emergency room triage, not first-come-first-served tickets.
The Hidden Math Behind Ad-Hoc Request Overload
Ad-hoc requests don't just steal time—they compound inefficiency in ways most leaders miss. When your senior engineer switches from deep architecture work to debug a sales demo issue, you're not losing one hour. You're losing the focus time before the interruption, the context-switching penalty, and the ramp-back period after. UC Irvine research puts this at 23 minutes just to regain deep focus.
With teams handling 15-20 ad-hoc requests weekly, you're bleeding roughly 30% of your capacity into thin air.
When developers know any Slack message could derail their day, they work in a defensive crouch. They avoid starting complex work because interruption feels inevitable. Quality drops. Morale tanks. Your best people start browsing LinkedIn during lunch breaks.
Most stakeholders submitting these requests have no idea about the downstream chaos. They see their ask as "just a quick database query" or "a small config change." They don't see your architect abandoning the API redesign that would prevent these fire drills in the first place.
Building Your Operational Triage Matrix
Emergency departments figured this out decades ago. Not every patient who says "urgent" gets immediate attention. They use classification systems that route cases based on actual severity, not arrival time or volume of complaints.
Eliminate team chaos and missed deadlines.
Temsly helps you assign, track & complete projects efficiently with full visibility.
- Centralized task management
- Real-time team communication
- Resource and deadline tracking
No credit card required
Start with four triage levels, each with clear criteria and response commitments:
Critical (Respond within 2 hours)
-
Production systems down affecting >1000 users
-
Security vulnerabilities actively being exploited
-
Regulatory compliance failures with immediate penalties
-
Revenue systems failing (can't process payments, can't close deals)
High (Respond within 24 hours)
-
Key customer escalations threatening renewal
-
Partial system degradation affecting <1000 users
-
Time-sensitive opportunities with quantified value >$50k
-
Blocking issues for other teams' committed deliverables
Standard (Respond within 72 hours)
-
Feature requests from strategic accounts
-
Performance improvements with clear metrics
-
Non-blocking bugs affecting <100 users
-
Data requests for business analysis
Scheduled (Next sprint planning)
-
Nice-to-have enhancements
-
Speculative analysis requests
-
Minor UI inconsistencies
-
Documentation updates
The magic isn't in the categories—it's in the enforcement. Every request must fit one bucket. No exceptions. No "Critical+" or "High-but-really-urgent" nonsense.
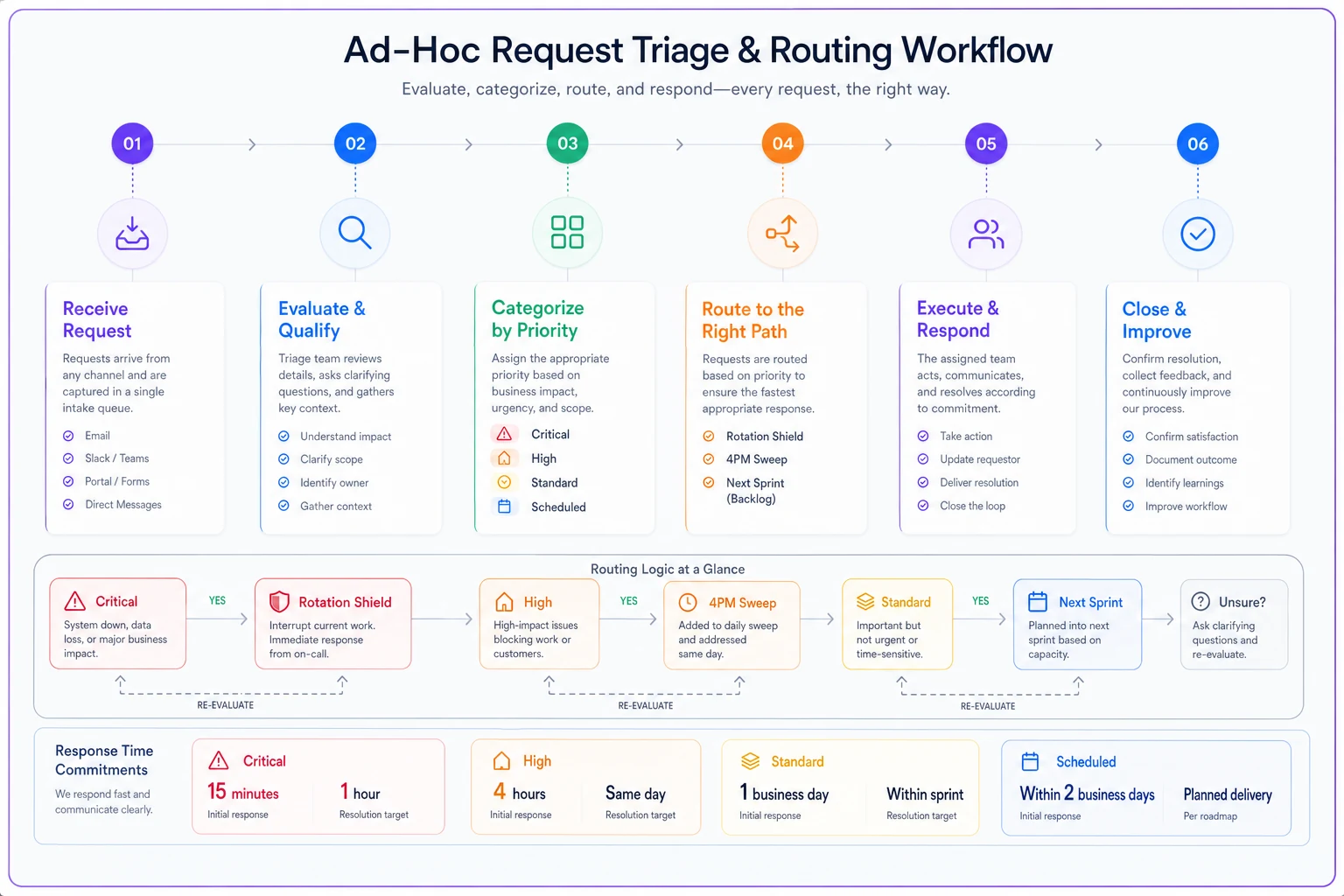
Use this flow to show routing and response times to stakeholders.
Small-Batch Handling Patterns That Actually Work
Traditional teams try to handle ad-hoc requests in two broken ways: interrupt everything immediately, or pile them into a massive backlog nobody ever touches.
The Rotation Shield Model
-
Assign one developer per week as the "interrupt shield." They handle all ad-hoc requests during their rotation while the rest of the team stays heads-down on planned work. The shield rotates weekly, so nobody gets burned out playing permanent firefighter.
-
Monitors the triage queue every 2 hours
-
Handles Critical and High priority items immediately
-
Batches Standard requests for afternoon processing
-
Documents solutions for future automation
-
Escalates only when truly blocked
This creates predictable interrupt windows while protecting 80-90% of your team's focus time. The shield person knows they're on interrupt duty, so they don't start deep work. Everyone else knows they're protected.
The 4pm Sweep Pattern
For teams that can't spare a full rotation, try the 4pm sweep. Every day at 4pm, spend 45 minutes clearing the ad-hoc queue as a team. Quick items get resolved immediately. Complex items get scoped for tomorrow's sweep or promoted to planned work.
Stakeholders learn the rhythm. Instead of random Slack bombs throughout the day, they submit requests knowing they'll get addressed at 4pm.
Stakeholder SLA Language That Sets Real Boundaries
Triage matrices and handling patterns mean nothing if stakeholders ignore them. You need explicit Service Level Agreements that stakeholders actually understand and respect.
Stop using vague language like "we'll get to it when we can" or "we'll prioritize appropriately." These phrases invite negotiation and create false expectations.
For Critical Requests:
"We guarantee initial response within 2 hours during business hours. Resolution timeline depends on complexity but will be communicated within the initial response. Requesting 'Critical' classification for non-critical items will result in automatic downgrade to Standard priority for all future requests from that stakeholder for 30 days."
For High Priority Requests:
"We commit to initial assessment within 1 business day. If accepted, work begins within 2 business days. If declined or reclassified, you'll receive written explanation with alternative options."
For Standard Requests:
"Requests enter our weekly planning cycle. You'll receive a decision within 5 business days: accepted (with timeline), deferred (with reason), or declined (with alternatives)."
Notice the penalty clause for Critical abuse? One fintech company implemented this after their VP of Sales marked seventeen requests as Critical in one month, including "make the login button more blue." After one penalty period, Critical requests dropped 85% and actual emergencies got proper attention.
The Request Intake Form That Filters Out Noise
Most ad-hoc requests die under scrutiny. Force requesters to think before they ask by requiring specific information upfront. Not essays—just enough friction to kill low-value requests while streamlining legitimate needs.
Your intake form needs exactly five fields:
-
1. Business Impact (required) "How many users affected? Revenue at risk? Compliance deadline? Be specific with numbers and dates."
-
2. Attempted Solutions (required) "What have you already tried? Who else have you asked? What workarounds exist?"
-
3. Success Criteria (required) "How will you measure if this is resolved? What specific outcome do you need?"
-
4. Urgency Justification (required for High/Critical) "Why can't this wait until next sprint? What happens if we address this next week instead of today?"
-
5. Stakeholder Commitment (required) "Who will test the solution? Who owns ongoing maintenance? Who's available for clarification?"
This form kills requests that shouldn't exist, provides context for faster resolution, and creates accountability on both sides. One e-commerce platform saw ad-hoc requests drop 40% just from implementing this form. Many "urgent" requests were really "I'm curious about something" disguised as operational necessities.
Converting Repeat Requests into Automated Workflows
If you're getting the same ad-hoc request repeatedly, you have a process failure, not a workload problem. The solution isn't handling it faster—it's eliminating the need for the request entirely.
Track your ad-hoc patterns for 30 days. You'll likely find:
-
The same data export request from finance every Monday
-
The same configuration update from sales every time they close a deal
-
The same "urgent" bug report that's actually user error
-
The same access request whenever someone joins a team
Each repeat request represents an opportunity for automation or self-service. That finance export? Build a dashboard they can access directly. The configuration updates? Create a form that triggers the change automatically. The bug report? Add better error messages or user training.
AI-powered operational software becomes genuinely useful here—not as magic, but as pattern recognition for repeat problems. Modern platforms can identify repetitive requests, suggest automation workflows, and generate initial self-service tools. Instead of your team manually handling the same customer data export request weekly, the system learns the pattern and creates a scheduled report that runs automatically.
If you're handling 20 repeat requests monthly at 30 minutes each, that's 10 hours of work. Spend 8 hours building automation once, and you've paid it back in under a month.
When Triage Systems Fail (And How to Recover)
Even great triage systems break under certain conditions. Recognize these failure modes before they destroy team trust:
The Executive Override
The CEO directly messages your lead developer about their pet feature, bypassing all process. Don't fight this head-on. Create an "Executive Sponsor" budget—explicitly reserve 10% of capacity for executive requests. When it's spent, show the tradeoff: "We can do this, but Feature X ships two weeks late."
The Crying Wolf Stakeholder
One department marks everything Critical until you stop believing them. Implement a "trust score." Start everyone at 100. Correctly classified requests maintain score. Misclassified requests lose 20 points. Below 60 points, that stakeholder loses self-classification privileges—you classify their requests for them.
The Scope Creep Special
A small request gets approved, then mysteriously grows into a multi-week project. Prevent this with explicit scope boundaries in your acceptance: "We'll add the export button. Additional formatting, scheduling, or delivery features are separate requests."
The Guilt Trip Gambit
"I know this isn't critical, but the customer is really upset and we promised them..." Customer promises made without engineering input don't create engineering obligations. Offer to join the customer call to explain realistic timelines, but don't accept transferred guilt as priority justification.
Real Scenario: How TechCo Went from Chaos to Control
A 200-person B2B SaaS company was drowning in ad-hoc requests. Their product team of 25 people was handling roughly 60 ad-hoc requests weekly, missing 40% of their roadmap commitments. Morale was shot. Three senior engineers had already left.
They implemented this exact triage system over six weeks:
-
Week 1-2
Defined the triage matrix and got leadership buy-in
-
Week 3-4
Rolled out the intake form and trained stakeholders
-
Week 5-6
Started the rotation shield model with senior developers
The results after 90 days:
| Metric | Before | After | Change |
|---|---|---|---|
| Weekly ad-hoc requests | 60 | 35 | -42% |
| Roadmap completion | 60% | 85% | +25% |
| Critical issue resolution | 8 hours | 3 hours | -62% |
| Developer satisfaction | 3.2/5 | 4.1/5 | +28% |
Sales and Customer Success actually preferred the new system. They knew exactly when their requests would be addressed and could set proper expectations with customers. The predictability was worth more than the illusion of immediate attention.
The Automation Opportunity Most Teams Miss
While triage systems manage the flow, the real win comes from systematically eliminating request categories entirely. Every ad-hoc request contains information about a missing capability in your operational platform.
Modern AI-assisted platforms can analyze your request patterns and automatically suggest process improvements. If sales repeatedly asks for customer usage reports before renewal calls, the system can recognize this pattern and automatically generate those reports 30 days before each renewal date.
This isn't about replacing human judgment—it's about removing repetitive coordination work that shouldn't exist. When your operational software can identify that certain types of configuration changes always follow the same approval pattern, it can create guided workflows that stakeholders can execute themselves with proper guardrails.
Choose platforms that learn from your actual operational patterns, not generic "best practices." Your ad-hoc request log is essentially a requirements document for operational improvements.
Making It Stick: The 30-Day Implementation Plan
Don't try to revolutionize your request handling overnight. Roll out changes systematically:
Days 1-7: Audit and Classify
-
Log every ad-hoc request for one week
-
Classify them using the triage matrix
-
Identify your top repeat offenders
-
Calculate actual time lost to context switching
Days 8-14: Design and Communicate
-
Create your intake form
-
Write your SLA statements
-
Present the system to stakeholders
-
Address concerns but don't negotiate core principles
Days 15-21: Pilot with One Team
-
Choose your most collaborative stakeholder group
-
Run the full triage system with them
-
Gather feedback on friction points
-
Refine the process based on real usage
Days 22-30: Full Rollout
-
Expand to all stakeholders
-
Start the rotation shield or 4pm sweep
-
Begin tracking metrics
-
Celebrate early wins publicly
After 30 days, you'll have enough data to show impact. Use this to reinforce the system and get buy-in for automation investments.
The Bottom Line
Ad-hoc requests will never disappear completely, nor should they. Legitimate urgencies exist. Markets shift. Customers have emergencies. But the current state where every request becomes an immediate interrupt? That's a choice, not a requirement.
Teams that thrive have learned to manage ad-hoc requests without sacrificing their planned work. They use operational triage to classify requests, small-batch handling to maintain focus, and clear SLA language to set boundaries. Most importantly, they treat repeat requests as opportunities for automation, not permanent fixtures of their workload.
Start with the triage matrix. Add the intake form. Implement the rotation shield. Within 60 days, you'll wonder how you ever operated without these systems. Your team will actually finish what they start. Stakeholders will get predictable responses. And maybe, just maybe, you'll ship that Q2 roadmap on time.
The chaos of ad-hoc requests isn't inevitable. It's a solvable operational problem. The only question is whether you'll solve it, or let it solve you.
Ad-hoc requests will never disappear completely, nor should they. Legitimate urgencies exist. Markets shift. Customers have emergencies. But the current state where every request becomes an immediate interrupt? That's a choice, not a requirement.
Teams that thrive have learned to manage ad-hoc requests without sacrificing their planned work. They use operational triage to classify requests, small-batch handling to maintain focus, and clear SLA language to set boundaries. Most importantly, they treat repeat requests as opportunities for automation, not permanent fixtures of their workload.
Start with the triage matrix. Add the intake form. Implement the rotation shield. Within 60 days, you'll wonder how you ever operated without these systems. Your team will actually finish what they start. Stakeholders will get predictable responses. And maybe, just maybe, you'll ship that Q2 roadmap on time.
The chaos of ad-hoc requests isn't inevitable. It's a solvable operational problem. The only question is whether you'll solve it, or let it solve you.
Ready to elevate your team's performance?
Join 2,000+ teams using Temsly to streamline workflows, boost productivity, and deliver projects on time.